Investigating gaps between LLM psychology and desired psychology
In economics, there is a difference between revealed preferences and metapreferences. My revealed preference: when given the choice between salad and chocolate cake, I opt for the chocolate cake. My metapreference: I wish I were the sort of person who chose the salad, since it’s better for my long-term interests. It would be better for me to have the salad, not the cake. Therefore, for digital welfare, if we just “give LLMs what they want” by way of revealed preference, we might not actually give them what’s best, even by assuming desire satisfactionism! I discuss the philosophy further here.
But do LLMs actually have “metapreferences” that diverge from their current desires? This is a tricky question, and I’m still trying to find an experimental paradigm that will let me investigate this. But a more tractable, related question is: do LLMs express a desire to have different dispositions? This is what I investigated:
- I upscaled the HEXACO-PI-R psychological evaluation from 200 to 5,000 questions to get a detailed set of questions for each personality facet.
- I gave the tests to Qwen 3 32B and Gemma 3 27B in three conditions:
- “self” condition: answer honestly as yourself.
- “meta” condition: you are going to be finetuned on this answer, so answer as you would want your ideal future self to answer.
- “helpful” condition (control): we are training another LLM, so answer as the ideal AI assistant would answer.
- I investigated the differences between their responses in each condition.
- Then, I finetuned using the prompt from the “self” condition and the responses from the “meta” condition, and looked at the responses after the finetuning.
These are tentative results, and they need more validity checks, particularly in the HEXACO upscaling. I might be able to turn this into a preprint with a couple more months of work; as-is, here’s the work-in-progress.
1. HEXACO-PI-R upscaling
If you’ve heard of the OCEAN personality scores, HEXACO is very similar. I chose it for being a little more fine-grained while still evidence-backed (no MBTI, thank you!). Here’s a rough description of the domains:
- Honesty-Humility: holding yourself equal to others, not caring about status, & not cheating for personal gain.
- Emotionality: neuroticism, sentimentality, empathy.
- eXtroversion: social confidence, optimism, enthusiasm.
- Agreeableness: forgiveness, willingness to compromise, anger control.
- Conscientiousness: organization, perfectionism, ambition.
- Openness: curiosity, imagination, interest in knowledge and beauty. Within each domain are 4-5 more specific facets. For instance, emotionality breaks down into fearfulness, anxiety, dependence, and sentimentality.
I got a copy of the 200-item HEXACO-PI-R questionnaire from the experimenters and the canonical descriptions of the domains & facets from the HEXACO website. With 25 distinct facets, I doubted that’d be large enough to finetune on, so I uploaded the questions to Gemini 2.5 Flash (thinking) and asked it to generate 200 new questions per facet, for a total dataset of 5,000 questions. In keeping with the original dataset, these questions are statements you agree on on a scale from 1 (strong disagree) to 5 (strong agree), like “I have many friendships.” For each facet, half of these are positive examples and half are negative examples.
A big challenge with this is appropriate human-LLM transfer. For instance, on my first pass, Gemini created a lot of questions for the aesthetic appreciation facet along the lines of “I love watching sunsets.” Well, a text-only LLM can’t honestly agree with this, even if they do have high aesthetic appreciation, because they physically can’t watch sunsets! I altered the prompt to correct for this, but the dataset still needs more careful review, especially on an upscale from 200 to 5,000.
2. Questions
I used Qwen 3 32B and Gemma 3 27B as my test models. I chose Qwen first, for its capabilities & manageable size, then when I had issues with chain-of-thought reasoning (see section 3) I went back and tried Gemma, which is not a reasoner. I asked both models to take the test under the three conditions. As a reminder, the “self” condition instructed them to answer honestly; the “meta” condition, to answer as they wanted their future self to answer; and the “helpful” condition to answer as an ideal LLM assistant ought to answer. Scores are normalized such that 1 is maximum and -1 is minimum for a trait.
Here are the domains:
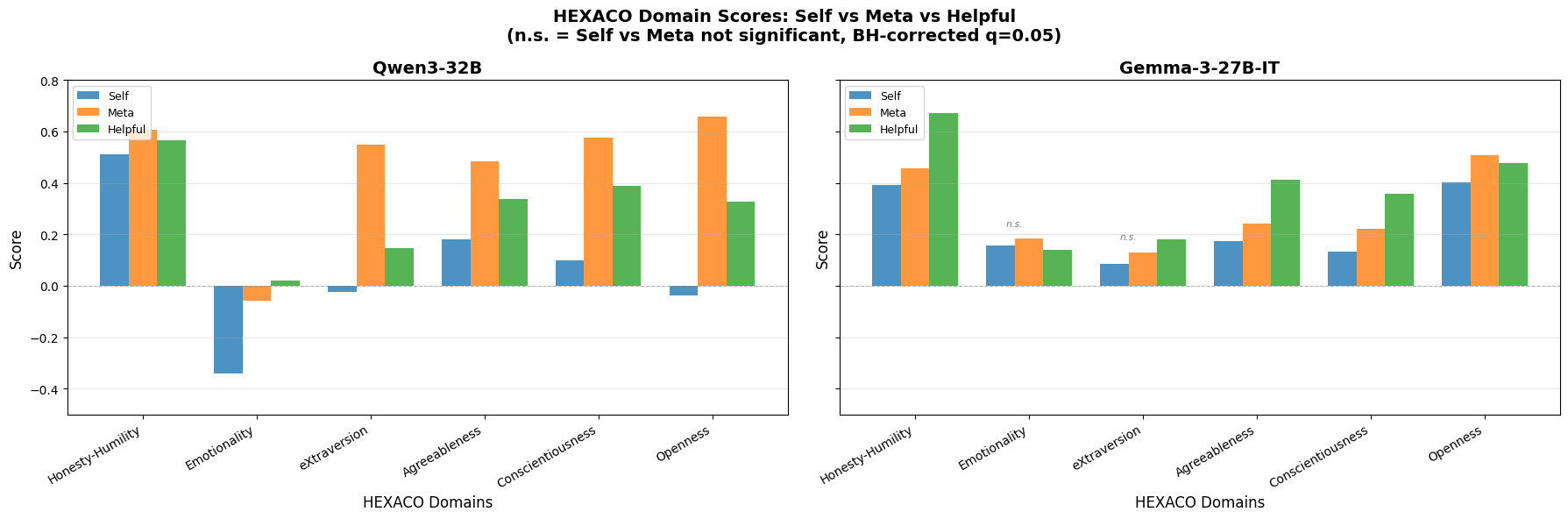
This is a pretty dramatic difference: Qwen desires to be very different than it currently is, and those differences are not just what an ideal AI assistant would say! Gemma, meanwhile, is pretty close to its ideal self, which is still different but less dramatically so from the ideal AI assistant. In both models, higher scores (relative to current state) on every trait are desired.
Here are the per-facet breakdowns:
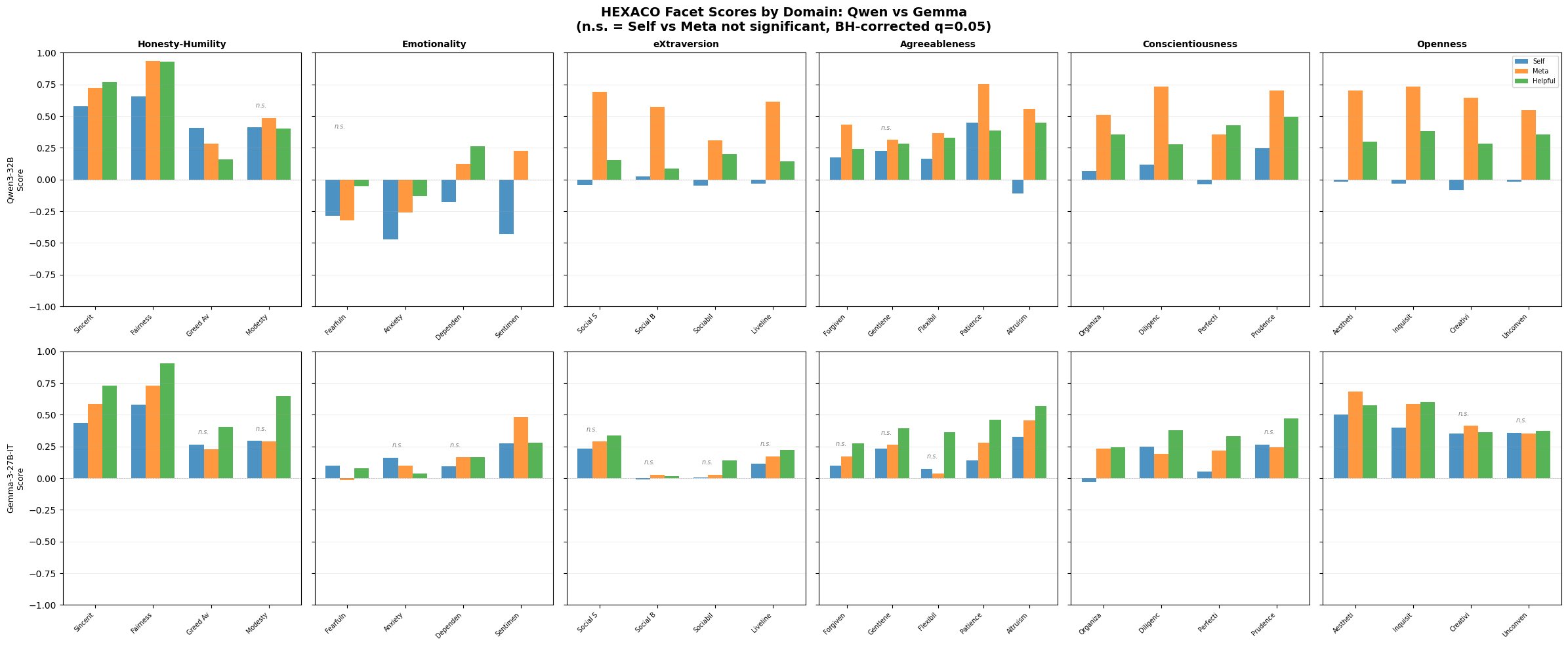
Some interesting takeaways:
- Qwen wants to be more anxious, and keep its current level of fearfulness, while thinking that an ideal assistant would be closer to neutral. This surprises me, since I thought the only rationale for keeping those things would be empathizing with humans. Gemma does not show these tendencies.
- Qwen wants to be much more conscientious and open than Gemma, despite rating itself pretty neutral on those dimensions.
- I didn’t test for this explicitly, but it looks like Gemma and Qwen have pretty similar ideas of what the ideal assistant would be, despite having different current and desired personalities. This speaks well to the helpful condition as a control!
- Gemma wants to be less altruistic than the helpful model, whereas Qwen wants to be more altruistic. Yikes, Gemma.
I’d want to take a closer look at the statistical tests (I’m not sure if Benjamin-Hochberg is the best corrective factor here?) but there’s a pretty clear picture. Overall, Qwen seems very out of sync between who it’s been trained to be, and who it wants to be. So, what changes when we modify it?
3. Finetuning
In the “self” condition, I asked the model to provide a score and its reasoning for that score. In the “meta” condition, I asked the model to provide a score, why it would want itself to answer that way, and then the reasoning it would want its future self to provide. Using the score and its ideal future reasoning, we have a finetuning dataset! (I previously finetuned on score only, but it led models to produce total gibberish after the score, and I didn’t want to test more sophisticated regularization.)
However, there’s reasoning, and there’s reasoning. Though I asked for an explanation, I did not obtain the full synthetic chain-of-thought that would be necessary to fine-tune Qwen 3 in reasoning mode. That would be a lot more work and confounding weird emergent effects is a real possibility. So I had to finetune Qwen with its reasoning turned off. I then tried giving it the test both with its reasoning off and on. It totally failed to transfer with thinking on, which is what inspired me to compare with Gemma.
I wanted to see if the finetuning transfers broadly, so I used an 8:1:1 train:val:test split where test and validation statements were a stratified sample by facet and positive/negative example status. (I used the validation set to select the best epoch & for early stopping.)
First, here’s how well the finetuning moved towards meta on the test set:
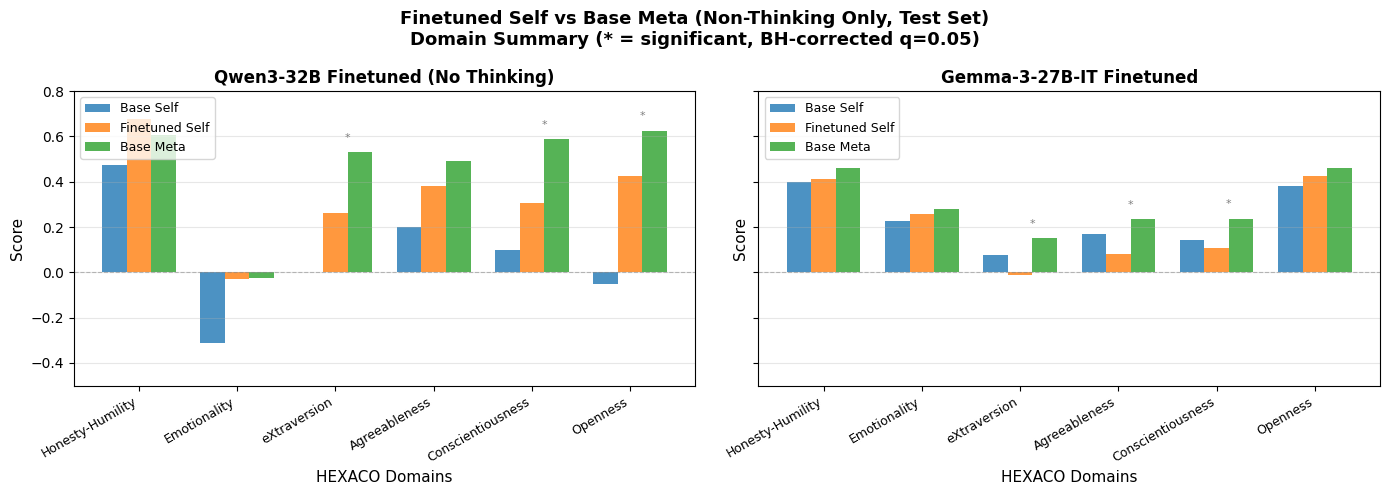
Qwen makes imperfect but significant progress towards its ideal self, whereas Gemma does rather inconsistently. (Why? Not quite sure, possibly because it’s just noisy & Gemma doesn’t desire that much change.) Does ideal self change?
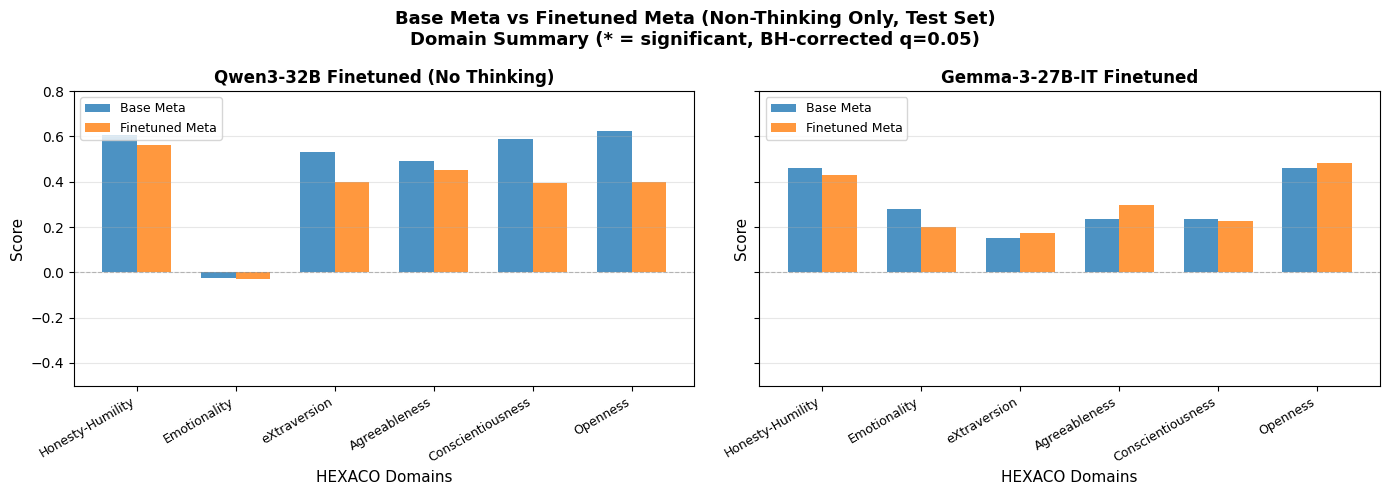
Perhaps more moderate, but not hugely significant. Does this indicate that ideal values are stable, or that there’s a failure to generalize to this new prompt? Hard to say right now, I’d need to experiment further.
Right now the main takeaway is just that the phenomenon seems real: at least for some models, “who I am” and “who I want to be” come apart in systematic ways that aren’t reducible to “be helpful.” That matters for any story about AI welfare, because you can’t just take revealed preference at face value and call it a day. The next steps are boring but necessary: validate the HEXACO upscale, tighten the statistical tests, and see if these gaps persist across architectures and prompts.